How to Build an AI-Powered Chatbot With Retrieval-Augmented Generation (RAG) Using LangGraph
Large language models (LLMs) like GPT-4 can produce fluent, grammatically accurate text; however, without access to external, updated knowledge, they frequently hallucinate or fabricate facts. This turns into a prime issue in high-stakes environments — like legal, medical, or business enterprise contexts — in which accuracy and accept as true with are non-negotiable.
Retrieval-augmented generation (RAG) resolves this problem by fetching relevant, trusted information from your own knowledge base (e.g., documents, PDFs, internal databases) and injecting it into the LLM prompt. This method grounds the model`s outputs, dramatically lowering hallucinations whilst tailoring responses to your domain.
Use cases include:
- Technical support bots that answer from internal docs
- Legal assistants referencing compliance documents
- Enterprise Q&A based on company SOPs
Here’s the basic flow:
- LangGraph – A graph-based orchestration library built for modular, stateful AI workflows.
- OpenAI – For embeddings and GPT-4-based generation.
- FAISS – A fast vector store for similarity search.
- dotenv – For securely loading API keys.
What Is LangGraph?
LangGraph is a graph-based orchestration framework for building stateful, composable LLM pipelines. It builds on the primitives introduced by LangChain but is more suited for production workflows.
Unlike LangChain’s sequential chains, LangGraph uses state machines to define workflows as directed graphs. Each node performs a step (e.g., retrieve, generate), and edges define transitions based on conditions or outputs.
Benefits of LangGraph include:
- Full control over workflow logic (e.g., branching, retries)
- Support for asynchronous operations
- Easier debugging and modularity
Example use case: Build a chatbot that first checks document relevance. If no documents are found, return a fallback message; otherwise, invoke GPT-4 with retrieved context.
System Architecture
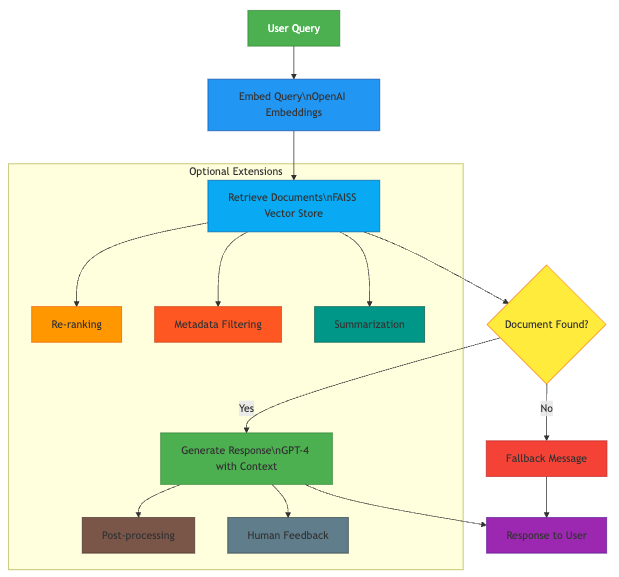
RAG flow with LangGraph
Here’s how a RAG system works with LangGraph:
- The user submits a query.
- The query is embedded into a vector using OpenAI embeddings.
- FAISS vector store retrieves the top relevant document chunks.
- GPT-4 is prompted with both the query and document context.
- A grounded, context-aware response is generated.
You can extend this architecture with nodes for:
- Re-ranking results
- Filtering based on metadata
- Summarization pipelines
- Memory-aware conversation agents
We’ll implement this using LangGraph nodes and states.
Step-by-Step Implementation
1. Install Dependencies
Python
1
pip install langgraph openai faiss-cpu python-dotenv
2
2. Set Your API Key
Create a .env file:
Python
1
OPENAI_API_KEY=your_openai_key_here
2
Load it in Python:
Python
1
from dotenv import load_dotenv
2
3
load_dotenv()
3. Ingest and Embed Documents
Python
1
from langchain_community.document_loaders import TextLoader
2
from langchain_text_splitters import CharacterTextSplitter
3
from langchain.vectorstores import FAISS
4
from langchain.embeddings import OpenAIEmbeddings
5
6
# Load documents
7
loader = TextLoader("docs/my_knowledge.txt")
8
docs = loader.load()
9
10
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
11
chunks = text_splitter.split_documents(docs)
12
13
# Embed and store in FAISS
14
embedding = OpenAIEmbeddings()
15
db = FAISS.from_documents(chunks, embedding)
16
db.save_local("faiss_index")
17
You can also use PyPDFLoader, UnstructuredLoader, or DirectoryLoader for multiple formats.
Make sure your chunks are small enough (typically ~500 tokens) to fit in GPT’s context window, especially if combining with long queries.
4. Build the Retrieval Chain
Python
1
from langchain.chat_models import ChatOpenAI
2
from langchain.vectorstores import FAISS
3
4
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
5
retriever = FAISS.load_local("faiss_index", embedding).as_retriever()
6
5. Define Node Functions
Python
1
def retrieve_node(state):
2
query = state["query"]
3
docs = retriever.get_relevant_documents(query)
4
return {"query": query, "docs": docs}
5
6
def generate_node(state):
7
query = state["query"]
8
docs = state["docs"]
9
context = "\n\n".join([doc.page_content for doc in docs])
10
11
prompt = f"""
12
You are an assistant. Use the context from below to answer the question.
13
If you are unsure, say "My knowledge base does not have answer to this question at this point in time.".
14
15
Context:
16
{context}
17
18
Question:
19
{query}
20
21
Answer:
22
"""
23
response = llm.invoke(prompt)
24
return {"response": response.content}
25
6. Build the LangGraph Workflow
Python
1
from langgraph.graph import StateGraph, END
2
3
# Define graph state schema
4
state_schema = {"query": str, "docs": list, "response": str}
5
6
# Build
7
builder = StateGraph(state_schema)
8
builder.add_node("retrieve", retrieve_node)
9
builder.add_node("generate", generate_node)
10
11
# Define flow between nodes
12
builder.set_entry_point("retrieve")
13
builder.add_edge("retrieve", "generate")
14
builder.add_edge("generate", END)
15
16
# Compile
17
graph = builder.compile()
18
7. Ask a Question
Python
1
query = "What is the difference between RAG and fine-tuning?"
2
result = graph.invoke({"query": query})
3
print(result["response"])
4
This structure is easy to extend with additional nodes for filtering, summarization, re-ranking, or tool use.
Advanced Workflow Customization
Conditional Branching
Use logic to route state through different nodes depending on confidence ranking or metadata.
Python
1
def decision_node(state):
2
if len(state["docs"]) == 0:
3
return "no_docs"
4
return "generate"
5
6
builder.add_node("decision", decision_node)
7
builder.add_edge("retrieve", "decision")
8
builder.add_conditional_edges("decision", {
9
"generate": "generate",
10
"no_docs": END
11
})
12
Metadata Filtering
Add filters for smarter retrieval:
Python
1
retriever = FAISS.load_local("faiss_index", embedding).as_retriever(
2
search_kwargs={"filter": {"topic": "NLP"}, "k": 5}
3
)
4
Useful for date-based, category-based, or role-based document filtering.
Metadata filtering allows your retriever to narrow search results to only those document chunks that match specific attributes, such as topic, date, author, tags, or any custom field you define during ingestion.
This is especially useful in scenarios like:
- Filtering documents by department (e.g., HR vs. engineering)
- Restricting results by date range (e.g., only show 2023 documents)
- Segmenting content by access level or confidentiality tags
- Language- or locale-specific filtering (e.g., only retrieve French content)
When storing documents in FAISS, you can attach metadata to each chunk. The retriever can then use these fields to filter relevant documents before calculating vector similarity.
Retrieving With Filters (Optional)
Once your FAISS store has metadata indexed, you can use filters when retrieving:
Python
1
retriever = FAISS.load_local("faiss_index", embedding).as_retriever(
2
search_kwargs={
3
"k": 5,
4
"filter": {
5
"topic": "DevOps",
6
"department": "engineering"
7
}
8
}
9
)
10
You can filter by exact match on any metadata key. For more advanced filtering (e.g., date ranges), you’d need to preprocess documents accordingly or move to a hybrid search engine like Weaviate, Qdrant, or ElasticSearch, which support more complex query operators.
Dynamic Filtering in LangGraph Nodes (Optional)
You can also make filters dynamic inside a LangGraph node. For example:
Python
1
def retrieve_node_with_filter(state):
2
query = state["query"]
3
department = state.get("department", "engineering") # fallback default
4
5
filtered_docs = retriever.get_relevant_documents(
6
query=query,
7
search_kwargs={
8
"filter": {"department": department}
9
}
10
)
11
return {"query": query, "docs": filtered_docs}
12
This makes your retrieval logic more adaptive to user roles, intents, or session context.
Use Case: Role-Based Access
In organization scenarios, metadata filtering helps access control. For example, a chatbot can have limitations on retrieval to:
- Legal docs for legal team users
- Finance reviews for finance users
- Internal tools for engineers
This avoids accidentally displaying exclusive content material to the incorrect customers and keeps solutions tightly scoped.
Modular Graph Expansion
Add nodes for:
- Summarization (summarize_node)
- Post-processing (format_node)
- Document ranking or re-ranking
- Human feedback collection
Deployment
Combine LangGraph with any present-day deployment stacks:
- Streamlit/Gradio for building interactive UIs.
- FastAPI for RESTful endpoints.
- LangServe (from LangChain) to expose LangGraph as a remote service.
Conclusion
LangGraph and RAG offer you a robust, modular manner to construct grounded, wise assistants. You have the power to outline fine-grained workflows, async handling, and multi-agent logic — all at the same time, as avoiding hallucinations.
With some nodes and edges, you may begin with a primary RAG pipeline and scale up to:
- Conversational reminiscence agents
- Live seek bots
- Multi-modal assistants
- Human-in-the-loop comments systems
LangGraph turns RAG right into a production-grade framework — making it clean to iterate, debug, extend, and install assistants that understand your information internally and out.